
네트워크 - TCP Congestion Control Algorithm
컴퓨터 네트워크를 공부하면서 정리를 한 내용들 입니다.
-참고 K-mooc 부산 대학교 유영환 교수님 : 컴퓨터 네트워크 강의
TCP 프로토콜에서 사용하고 있는 Congestion Control 매커니즘들을 살펴봅니다.
처음 Congestion control 알고리즘을 TCP에 적용 한 것이 TCP Tahoe이고,
이것을 발전 시킨 Reno, NewReno와 SACK(Selective ACK)도 알아 봅니다.
이 4가지를 선택한 이유는 실제로 표준으로 채택되어 있는 것들이고, 실제로는 더 다양합니다.
TCP Tahoe(1988)

1988년에 Van Jacobson이 제안을 한 것으로,
slow start, congestion avoidance와 fast retransmit를 사용합니다.
오른쪽의 그래프는 동작의 과정을 나타낸 것 입니다.
SS가 slow start이고 CA가 congestion avoidance로 매우 단순한 형태입니다.
처음에 연결이 수립 되어서 congestion window size가 두 배씩 이렇게 증가 하다가
타임 아웃이 발생 하면 congestion window size가 다시 초기 값으로 줄어 버리는 것입니다.
그리고 다시 천천히 증가 시키고 제일 첫 번째 경우에는 처음에 연결이 수립 되었기 때문에
slow start threshold 값이 없는 상태였지만 한 번 loss를 겪거나 congestion을 겪고 나면
window size 절반 값을 slow start threshold 값으로 셋팅 한 상태이기 때문에,
slow start를 하다가 ssthresh 넘어 서게 되면 addictive increase 방식으로 천천히 증가시킵니다.
그러다가 그 요구가 congestion avoidance 구간이 되겠고
다시 congestion을 발견 하면 다시 1로 줄이고 slow start threshold 값은 합니다.
TCP Tahoe의 특징적인 점은 fast retransmit을 도입 했다는 것입니다.
타임 아웃이 발생 하기 전이라도 세 개의 중복된 ACK를 받으면
바로 congestion 메커니즘을 동작 해서 타임아웃이나 fast retransmit에 동일하게
congestion window size를 1로 줄여서 이 문제를 해결 해 나간다는 것입니다.
TCP Reno(1990)
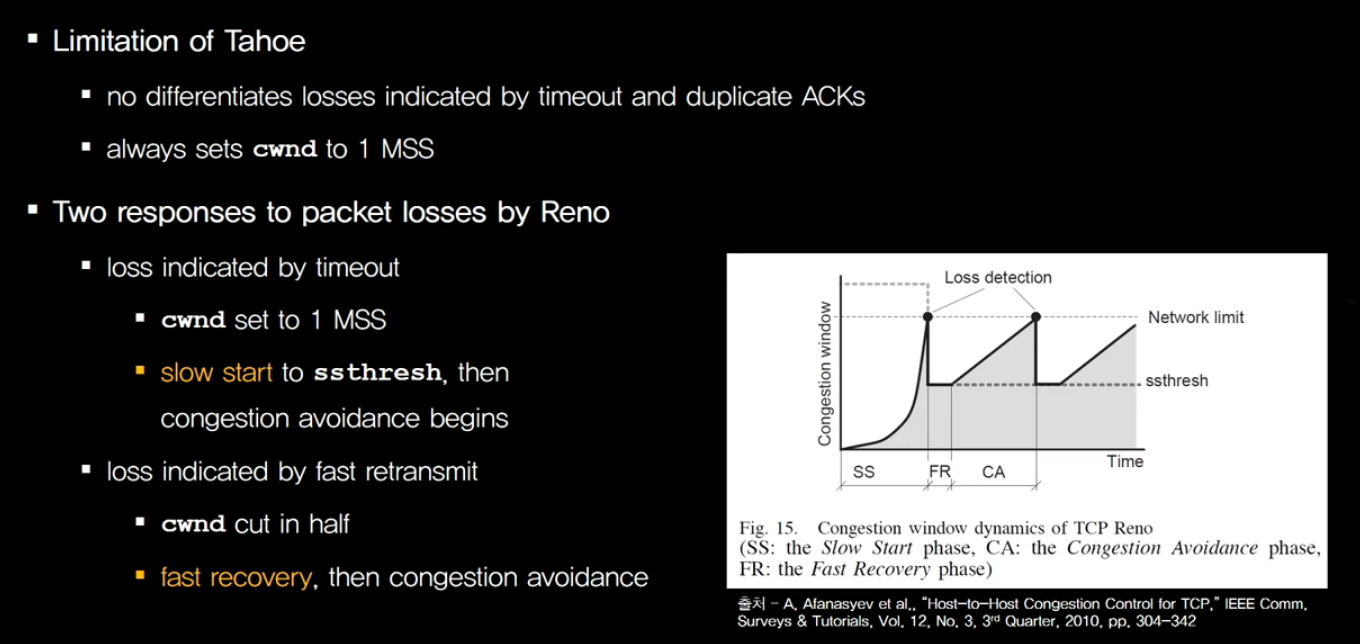
그런데 TCP Tahoe를 제안하고 나서 TCP Tahoe에도 개선 할 만한 점이 있었습니다.
TCP Tahoe는 타임 아웃의 경우와 fast retransmit 이 두 가지를 구별하지 않았던 것입니다.
타임 아웃이 발생하거나 fast retransmit이 발생 하면 loss가 발생한 것이기 때문에
congestion window를 무조건 1로 줄임으로써 throughput이 확 줄어드는 단점이 있었습니다.
그래서 이 둘을 구별시켰습니다.
타임 아웃의 경우에는 TCP Tahoe하고 동일한 방식으로 동작하게 하고,
fast retransmit, 세 개의 duplicate ACK를 받아서 어떤 패킷의 분실을 감시 한 경우에는
congestion window size를 반 정도만 줄이고 fast recovery라는 단계로 가서
새로운 ACK가 도달 하면 다시 congestion avoid 단계로 가서 동작을 하는 것입니다.
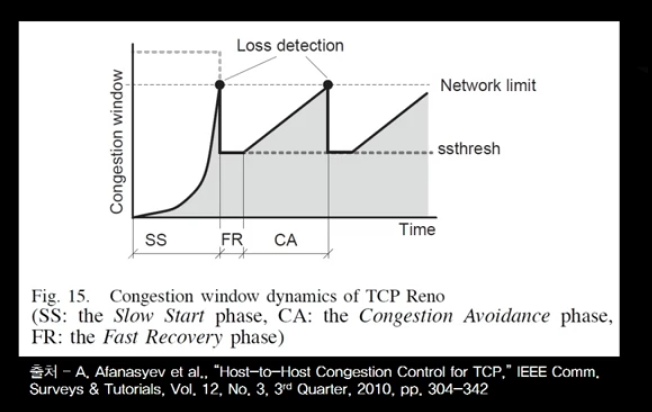
오른쪽의 그래프는 동작의 과정을 나타낸 것 입니다.
처음에 연결이 수립 되어서 이렇게 congestion window size가 증가 하다가 loss를 발견 했는데
타임 아웃 때문에 발견 한 것이 아니라 fast retransmit 때문에,
Tahoe처럼 congestion window size를 반으로 줄여서, fast recovery 단계에 있다는 것입니다.
fast recovery에 있다가 새로운 ACK가 도달 하면 이 때부터 다시 congestion avoid 단계에 들어갑니다.
Fast Recovery

window size를 반으로 줄이고 loss를 발견 하기 까지의 non-duplicate ACK 이외에
새로운 ACK를 받을 때 까지 대기를 하는 것입니다.

-
State 1 : 처음 congestion window size입니다.
-
State 2 : loss를 detection한 상태입니다.
세 개의 중복 ACK에 의해서 loss를 발견 한 것입니다.
그 경우에 congestion window size를 이렇게 반으로 줄였습니다.
- State 3 : fast recovery에 들어 간 단계에서도 새로운 duplicate ACK가 날아 올 수 있습니다.
즉, 새로운 duplicate ACK가 날아 오면 이 뒤에 전송 한 패킷들이 도착하고 있다는 뜻입니다.
그러면 도착 할 때 마다 그 만큼씩 congestion window를 약간 이동 시켜 줍니다.
-
State 4 : 이 동작을 하다가 congestion window가 아까 처음 문제가 발생 하기 전 까지 보냈던 데이터를 벗어나서 까지 전송 할 수 있는 것입니다.
-
State 5 : 재전송 한 패킷이 잘 도달하게 되면 뒷 부분이 모두 한꺼번에 처리가 될 수 있어서 여기에 non-duplicate ACK가 오면 fast recovery에서 끝납니다.