
[Redis]Redis Cluster 환경에서는 왜 Multi 명령어를 지양해야 하는가?
우리 회사에서는 Redis Cluster 환경을 사용하고 있다.
기존의 Redis Master/Slave 형상에서 Redis Cluster의 환경으로 변경되었고,
어떤 차이인가와 Multi 명령어를 사용하면 안되는가 알게된 내용을 간단하게 회고하며 정리해본다.
이 글에서는 Redis에 대해서나 명령어에 대한 내용은 간략하게만 설명할 예정이다.
Redis란 무엇인가?

Redis는 Remote Dictionary Server의 약자로, 인메모리 기반의 Key-Value의 DB이다.
풀어서 작성해보면?
위 처럼말 작성하면 복잡할 수 있으니 단어들을 풀어서 설명해보자면 다음과 같다.
Remote(원격) : 클라이언트가 Redis 서버에 원격으로 연결이 가능하다.
Dictionary(사전) : 데이터를 키-값(Key-Value) 쌍으로 저장하는 구조를 가진다.
Server(서버) : 클라이언트의 요청을 처리할 수 있도록 데이터에 대한 저장, 검색, 관리에 대한 역할을 수행한다.
인메모리 기반 : 데이터들을 메모리 안에 저장하고 처리한다. 메모리 기반으로 되어있기 때문에 디스크 기반인 데이터베이스들 보다 빠른 속도를 제공한다.
이것에 대한 사용법들은 아래의 공식문서를 참고하거나, 다른 글을 찾아가는 것을 권장한다.
공식문서 Link : 공식문서
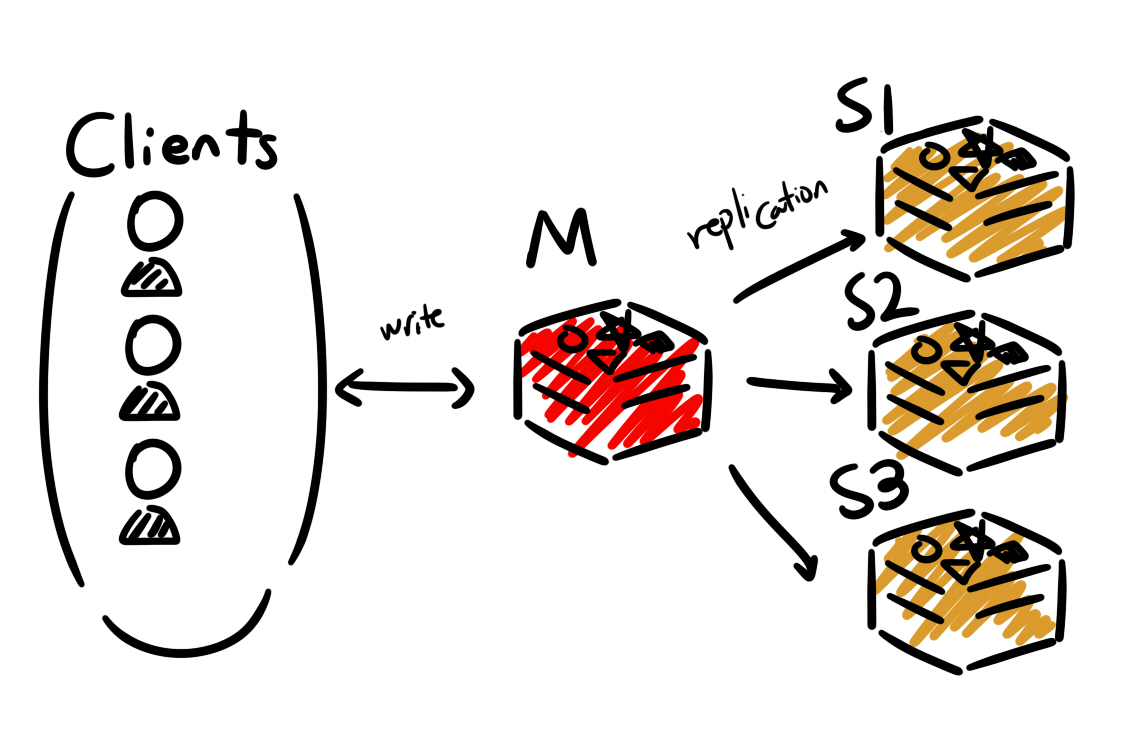
Redis Master/Slave
Redis Master/Slave
Master / Slave 구조는 데이터의 복제와 읽기/쓰기 작업을 분리하여 성능과 가용성을 높이는 기본적인 아키텍쳐이다.
Master의 역할 : 모든 쓰기(Write) 작업을 처리한다.
Slave의 역할 : Master의 데이터를 복제해서 가지고 있는다. Read 작업을 처리하며 Master의 부하를 분산시킨다.
Slave가 여러개인 상황에서 Master가 고장이 난다면 Slave 중 하나를 Master로 FailOver시키는 방안이 가능하다.
특징
1.구성이 비교적 간단하다. (장점)
2.Slave들에 동일한 데이터를 가질 수 있도록 복제되어 있기 때문에 읽기 요청을 분산 처리하기 좋다. (장점)
3.복제된 데이터를 가지고 유지하므로 데이터에 대한 손실 위험을 줄일 수 있다. (장점)
4.모든 쓰기가 Master에 집중이 되므로 많은 양의 데이터를 쓰는 경우 부하가 쌓여 병목현상이 생길 수 있다. (단점)
5.모두가 같은 데이터를 복제하고 있기에, 데이터를 분산하지 못해 저장 용량에 대한 한계가 명확하다. (단점)
Master-Slave 구조의 장애 처리는?
(Slave가 여럿있다는 가정하에 진행한다.)
Master가 장애 발생 시, Slave 중 하나를 새로운 Master로 승격시킨다.
승격된 새로운 Master에 다른 Slave들이 재연결하여 복제를 수행한다.
이를 수동으로 처리해 주는것이 불편할 수 있기에
확장된 개념으로 Redis Sentinel이 있으며 이 경우 자동 장애 조치(Auto Failover)를 수행할 수 있다.
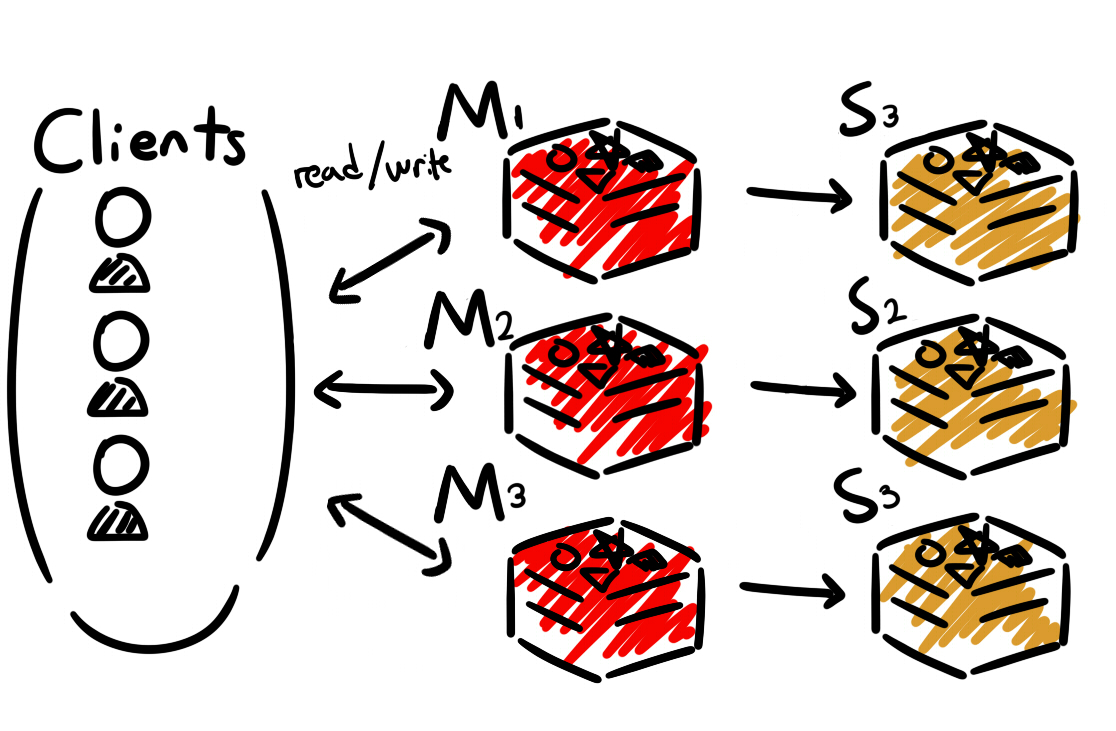
Redis Cluster
Redis Cluster
Master의 역할 : 모든 읽기와 쓰기 작업을 처리한다.
Slave의 역할 : 데이터들이 Sharding되어 분산되어 있다.
Sharding이란? 데이터를 여러 노드로 분산하여 처리량 및 용량을 확장할 수 있다.
특징
1.최소 노드 수는 6개 이다.
2.여러 master노드로 구성되어 단일 실패 지점을 제거할 수 있다.(장점)
3.노드를 추가하여 쉽게 확장할 수 있다.(장점)
4.데이터를 16384개의 해시 슬롯(hash slot)으로 나누어 여러 노드에 분산 저장한다.
5.키는 CRC16(key) % 16384를 통해 해시 슬롯에 매핑되며, 각 노드는 특정 슬롯 범위를 담당한다.
이에 대한 자세한 내용은 공식문서에서 Cluster Spec에서 확인할 수 있다.
예를 들어 다음과 같다.
-
노드 A: 슬롯 0~5460
-
노드 B: 슬롯 5461~10922
-
노드 C: 슬롯 10923~16383
본론으로 들어가면..
위에서 작성한 것 처럼 Redis Cluster는 데이터를 여러 노드에 분산하여 저장한다.
Multi 명령어를 사용하게 된다면 하나의 트랜잭션 내의 키들이 다른 노드에 저장될 수 있어,
동시에 여러 key에 접근하는 것이 불가능해진다.
동시에 여러 key에 접근한다는 의미는 Redis 연산을 수행할 때 인자로 여러 개의 key를 넘기는 상황을 의미한다.
대표적인 명령어로는 mget, mset을 예로 들 수 있다.
spring doc에서 메소드 검색으로 multiGet 확인할 수 있다.
Multi 명령어로 여러 키를 동시에 조작하려 들 때, 한 명령어에서 단일 트랜잭션으로 처리하기가 어려워진다.
그렇기에 동일한 노드에서 트랜잭션을 실행하는 방식으로 동작해야 한다.
트랜잭션을 사용하고자 한다면?
첫번째, 하나의 node에 몰아넣는 방법 - hash tags
Redis의 key를 중괄호로 묶으면, 중괄호 내의 key를 hash한 결과값을 바탕으로 노드에 할당하게 된다.
-- 예시
key:{hashExample}:example
hash tag를 포함한 key는 hash tag 내부에 있는 문자열에만 hash를 진행한다.
따라서 같은 hash tag를 가진 다른 key도 같은 node에 들어가는 것을 보장할 수 있다.
이 외에도 다른 여러 케이스가 존재하며, hash tags의 자세한 사용법은 Redis 공식 문서에서 확인할 수 있다.
hash tags는 트랜잭션뿐만 아니라 아래와 같이 동시에 여러 key에 접근하는 연산에도 적용하여 사용할 수 있다.
즉, 동일 node에서 돌아가야만 하는 기능들에 적용할 수 있다.
그러나 여러 node에 분산되는 것이 아니라 하나의 node에만 집중될 수 있다는 것은
이것은 분산 시스템을 위한 Redis Cluster의 장점을 무시하고 기존의 Master/Slave와 다른 바 없다.
따라서 hash tags를 사용하는 것은 여러가지 상황들을 고려 후 결정해야 한다.
두번째, 클라이언트 측에서 단일 방식으로의 로직 구현
multiGet 명령어를 Override한 뒤 단일 Get 방식으로 변경하는 것도 일종의 방안이다.
public List<String> multiGet(List<String> keys) {
List<String> results = new ArrayList<>();
for (String key : keys) {
String value = redisTemplate.opsForValue().get(key);
results.add(value);
}
return results;
}
Redis Cluster의 데이터 분산 특성에 맞게 동작한다.
각 키에 대해 개별적으로 접근하므로 여러 노드에 분산된 데이터를 처리할 수 있다.
클러스터 환경에서의 제약사항을 우회하여 안정적으로 동작한다.
다만, 원래의 MultiGet보다 네트워크 요청이 증가할 수 있다.
키의 수가 많을 경우 성능 저하가 발생할 수 있으므로, 한 번에 처리하는 키의 수를 제한하는 것이 좋다.
결론
다른 여러가지 방안들이 있겠지만,
모든 방법들은 장 단점이 존재하기 때문에 현실적인 상황을 고려하여 확인해보고 결정하도록 한다.
참고 링크 :
초보 개발자를 위한 Redis Cluster Migration 가이드라인