
네트워크 - Introduction to Routing
컴퓨터 네트워크를 공부하면서 정리를 한 내용들 입니다.
-참고 K-mooc 부산 대학교 유영환 교수님 : 컴퓨터 네트워크 강의
Two Key Functions in Network Layer
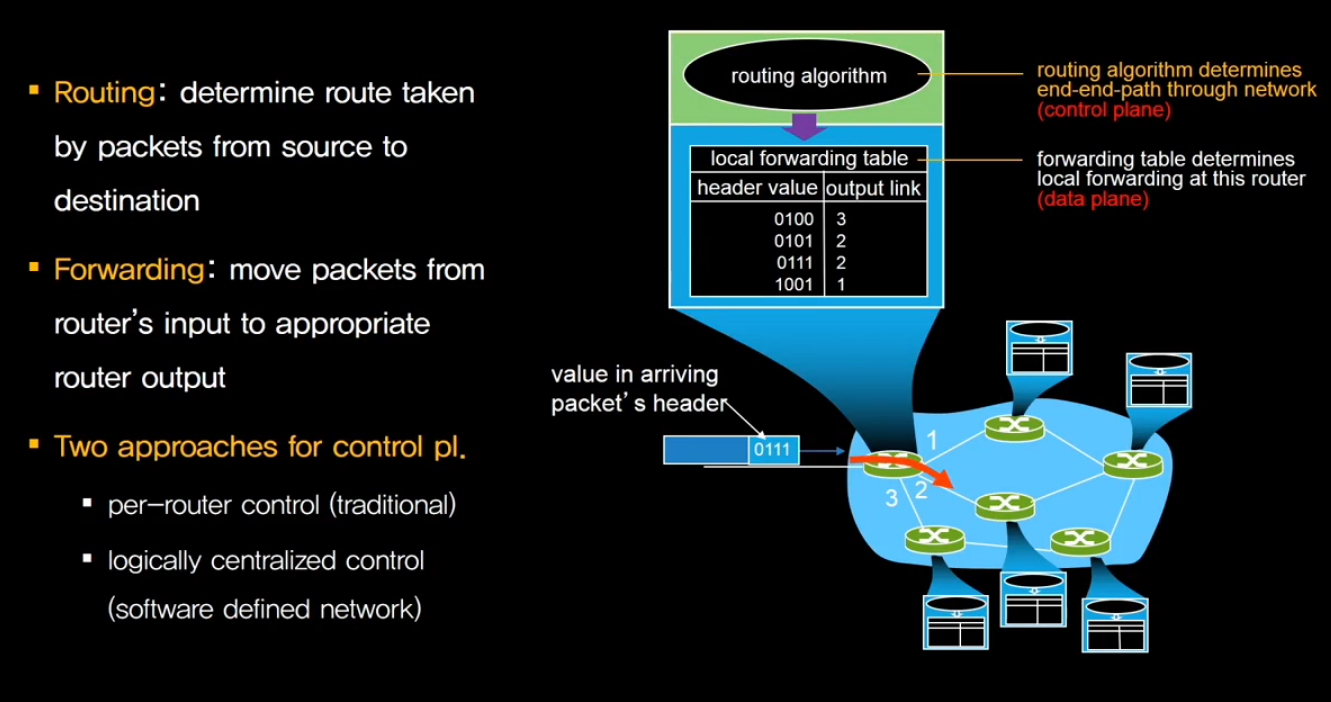
네트워크 레이어의 두 가지 핵심적인 기능으로
라우팅과 포워딩이 있습니다.
포워딩은 가지고 있는 포워딩 테이블에 의거 해서 외부에서 날아 온 데이터그램을
받은 데이터그램의 목적지 주소를 보고 일치하는 entry를 찾아서
거기에 맞는 output 링크로 내 보내는 것 이었습니다.
그리고 이런 포워딩 테이블을 만드는 데 있어서
기본적인 기능을 하는 것이 라우팅 알고리즘 입니다.
즉, 포워딩 테이블에 의거 해서 포워딩 기능을 수행하는 것이 라우터의 기능 입니다.
그런데 control plane이라는 라우팅 알고리즘의 기능은
기존 전통적인 네트워크에서는 모든 라우터에서 각자 수행이 되었습니다.
현재는 SDN에서는 중앙 집중형으로, 중앙 서버가 수행하는 식으로 합니다.
Per-router Control Plane

Tranditional network에서는 라우팅 알고리즘이 라우터마다 별도로 수행이 됩니다.
그래서 각 라우터에는 라우터 알고리즘이 있고 그 라우팅 알고리즘들 끼리
서로 정보를 공유 한 뒤에 그것에 따라서 포워딩 테이블을 만들게 됩니다.
그래서 each and every router 이라는 작업을 수행 한다고 이야기 합니다.
Logically Centralized Control Plane
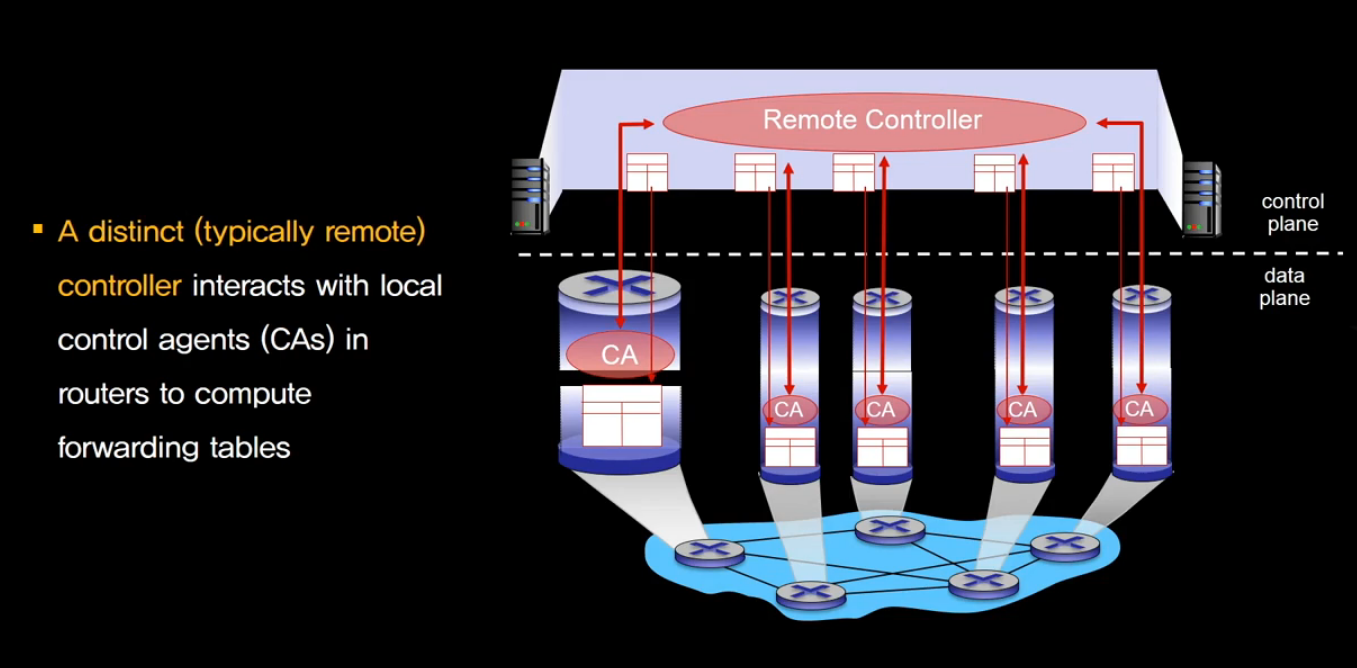
SDN에서는 외부에서 모든 라우터들이 가지는 정보를 수집 한 뒤,
그 정보를 기반으로 포워딩 테이블을 만들어서
그것을 다시 각 라우터한테 전달 해 주면
각 라우터들은 그것에 따라서 포워딩을 합니다.
앞의 모든 개별 라우터들이 이런 라우팅 알고리즘을 수행 하는 것 보다
remote controller가 이것을 수행 하면 전체적인 네트워크 정보를
더 많이 얻을 수 있게됩니다.
더 많은 정보를 기반으로 포워딩을 결정 하기 때문에
보다 효율적인 길을 선택할 수 있다 하는 것이 장점이 됩니다.
Routing Protocols
기존 traditional network, IPv4에서 주로 어떻게 수행을 했었는지 살펴봅니다.

라우팅의 목적은 “좋은 경로”를 찾는 것이 라우팅의 목적입니다.
그런데 좋다는 여러 가지 기준이 있을 수 있습니다.
일단 비용이 가장 적은 경로가 될 수도 있고, 가장 빠른 경로가 될 수도 있고,
가장 혼잡이 적은 경로가 될 수도 있습니다.
이런 라우팅 연구에서 많이 쓰이는 방식이
그림의 아래에 있는 그래프를 기반으로 하는 것 입니다.
u, v, w, x, y, z 이런 것들은 라우터,
이것들을 하나의 라우터 집합으로 두고 보통 N이라고 표현을 합니다.
다음에 각 라우터들 사이를 연결하는 간선들을 (u,v), (u,x)
괄호를 해서 한 쌍으로 링크로 표현합니다.
Path Cost

어떤 경로를 선택하는데 있어서 코스트가 들기 마련입니다.
링크 코스트는 이렇게 링크마다 값이 주어집니다.
목적지 까지의 경로가 가지는 코스트는 적으면 적을수록 좋습니다.
라우팅 알고리즘에 주어지는 질문은
어떤 두 라우터, u와 z 사이에 가장 최소 비용의 경로는 무엇이냐?
라는 것이고, 이것에는 다양한 방식이 사용 될 수 있습니다.
가장 간단하고 일반적인 방식으로는, 모든 링크가 비용이 같다고 보는 것 입니다.
왜냐하면 링크를 거쳐가는데 있어서
transmission delay, propagation delay는 별로 크게 중요하지 않고,
중간에 queueing이 일어나서 delay가 많이 증가 할 수 있기 때문에
hop 수가 적은 것이 좋다고 판단한 것입니다.
Routing Algorithm Classification
라우팅 알고리즘 분류 방식에는 크게 두 가지가 있을 수 있습니다.

하나는 static과 dynamic으로 분류하는 방법입니다.
static
말 그대로 정적인 것입니다.
각 패스 또는 라우트를 관리자가 결정 해 주는 것으로,
중간에 있는 라우터들을 다 수동으로 메뉴얼하게 설정 해 주는 것입니다.
그러다가 중간에 네트워크의 상황이 바뀌면
administrator가 라우터들에 접속을 해서 이 값을 수동으로 바꾸는 것입니다.
dynamic
라우터들이 알아서 정보를 주고 받은 뒤에 거기에 따라서 길을 선정 합니다.
같은 source와 destination이라 하더라도
네트워크 상황에 따라서 route 또는 path가 변할 수 있고, 빠르게 대응할 수 있습니다.
다른 하나는 Global과 Decentralized로 분류하는 방법입니다.
Global
모든 라우터들이 전체 네트워크 topology를 완벽하게 알고 있고
각 네트워크에 있는 모든 link cost와 링크의 상황들을
다 안 상태에서 경로를 결정하는 경우를 뜻합니다.
Decentralized
decentralized는 직접 연결 되어 있는 이웃들만 알고
다른 node들에 대해서는 가기 위한 총 경로 비용과
그 경로 비용으로 보내기 위해서 어떤 node를 선택해야 하는지 정도만 알고있습니다.