
네트워크 - Error Detection & Correction(4)
컴퓨터 네트워크를 공부하면서 정리를 한 내용들 입니다.
-참고 K-mooc 부산 대학교 유영환 교수님 : 컴퓨터 네트워크 강의
FEC: Convolutional Code
이전 포스트에서는 Forward error correction의 hamming code에 대해 살펴봤습니다.
요즘에 많이 쓰이는 기술 중에 하나는 convolutional code라는 것이 있습니다.
hamming code와 convolutional code의 차이를 살펴 보면
hamming code
hamming code는 데이터 블록 단위로 코드워드로 대체가 되어서 전송 됩니다.
그럼으로써 에러가 발생 했을 때 원래 데이터가 무엇이었는지 찾아내는 방식이
block code를 사용한 hamming code 기술이었습니다.
일반적인 데이터면 가능하지만 음성 같은 연속적으로 들어오는 데이터의 경우에는
적용하기가 매우 힘들어 집니다.
convolutional code
convolutional code라는 것은 매 비트를 전송하려는 코드워드로 바꿀 때
이전의 히스토리가 현재 비트를 전송하려는 코드로 변경 시키는데도
영향을 주게 됩니다.
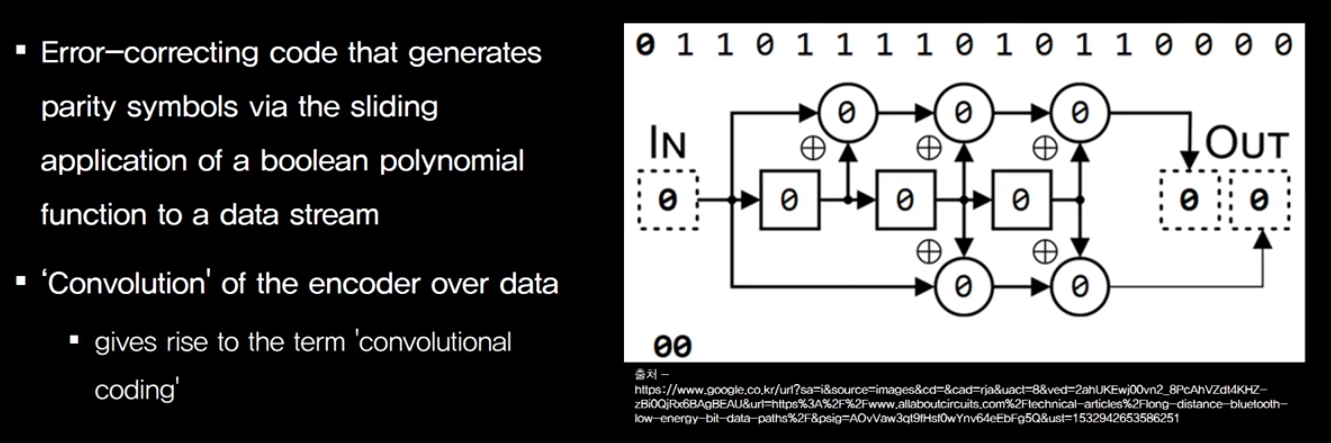
For example
그래서 예를 들면 오른쪽에 있는 형태의 코드워드를 만들 수가 있게 됩니다.
IN하는 1 bit가 OUT하는 2 bit로 만들어져서
sender가 전송하는 비트가 된다는 것 입니다.
그래서 1 bit가 2 bit의 OUT을 만들기 때문에 시스템의 code rate는 1/2입니다.
이것은 1 bit가 그냥 단순히 00으로 바뀌고 11로 바뀌는 것이 아니라
어떤 특별한 규칙이 있습니다.
첫 비트 0이 들어 왔을 때 레지스터들이 그림처럼 3단계가 있다고 가정합니다.
그래서 레지스터에서는 앞서 들어왔던 데이터를 기억 하게 됩니다.
첫 번째 비트 같은 경우에는 처음의 초기값 000,
앞에 세 개 레지스터의 000이 들어와 있다고 가정을 하고
Exclusive 연산을 해서 이렇게 현재 들어 온 데이터가
바로 앞선 데이터와 exclusiveOR 연산을 하고
그 결과 값이 다음 레지스터에서 다른 데이터와 exclusiveOR 하는 식으로 진행됩니다.
앞서 들어왔던 bit의 값을 레지스터에서 기억하고 연산하기 때문에
똑같은 0이 들어가도 똑같은 결과값이 나오지 않습니다.
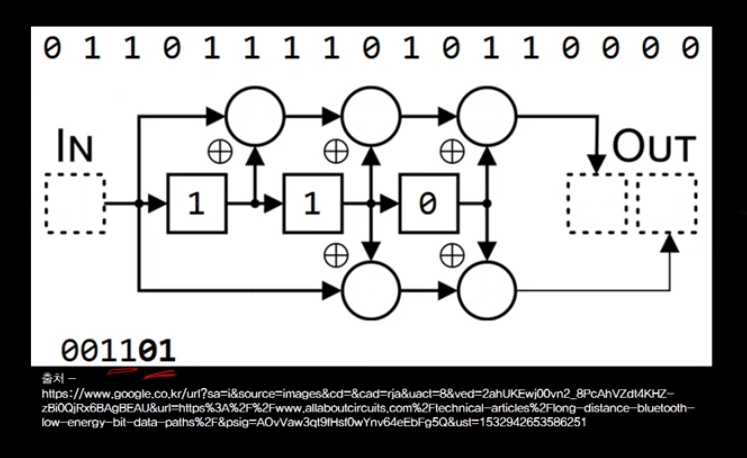
그래서 이런 경우에 굉장히 에러를 감지하고 수정하는 기능이 굉장히 강해집니다.
왜냐하면 이전의 히스토리가 있기 때문에 지금 데이터는 code rate이 1/2,
redundant한 데이터를 한 비트 밖에 더 보내지 않는 것처럼 보이지만
사실은 지금 만들어 내는 code rate은 이전에 세 비트가 뭐였냐에
따라서 그 값이 바뀌는 것이기 때문에 히스토리를 알고있음으로 인해
엉뚱한 코드가 들어 올 수는 없고 에러가 발생 하면 그것이 0이거나 1이었을 때
감지하고 수정해 낼 수가 있게 됩니다.
그래서 convolutional code라는 것은 이런 식으로 쓰이고
요즘에 블루투스에서 이런 식으로 사용을 하고 있습니다.